ジョブキューイングとは
過去にRabbitMQの記事でも触れたことがあるのですが、今回はLinuxでジョブキューイングを行う方法をまとめてみました。
ジョブキューイングはまず何か時間の掛かる処理(ジョブ)を、キューと呼ばれる場所に貯めていきます。そして溜まったジョブを逐次実行していくという仕組みのことです。
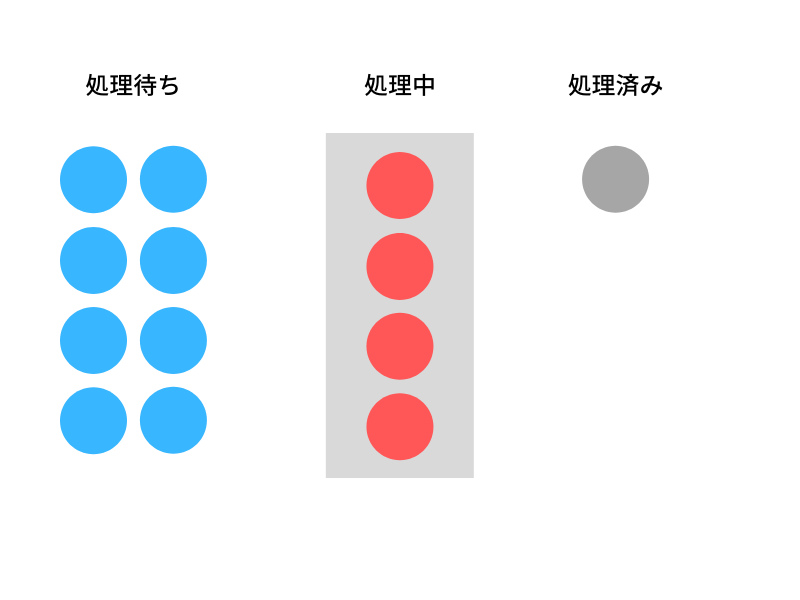
例えば時間の掛かる計算を何度もしないといけない状況を想像してみて下さい。これを一度に全て実行しようとすると完了するまで他のことが出来なくなってしまいます。
こんな時にジョブキューイングでは処理を細かくジョブに割りキューに詰めてからバックグラウンドで逐次実行することでリソースを独占することなく処理出来るのです。
準備
Linuxでジョブキューイングするには様々な選択肢があるのですが、今回はtask-spoolerを使用します。下記のコマンドを実行して下さい。
$ brew install task-spooler使い方
基本的な使い方は下記の通りです。
ジョブをキューに貯める
$ ts [コマンド]
$ ts sh hoge.sh ← 例
ジョブの一覧を見る
$ ts -l
ジョブのPIDを見る
$ ts -p [ジョブID]
$ kill [PID] ← ジョブを強制終了するコマンド
ジョブの結果を全削除
$ ts -C
task-spoolerサーバを終了する
$ ts -K試しに下記のシェルスクリプトで試してみます。これは10秒間なにもしないシェルスクリプトです。
#!/bin/bash
START_TIME=`date +%s`
CURRENT_TIME=`date +%s`
while [ $((CURRENT_TIME - START_TIME)) -lt 10 ]
do
CURRENT_TIME=`date +%s`
donehoge.shを続けて2回実行した状態でジョブ一覧を見てみると下記の様になります。
$ ts -l
ID State Output E-Level Times(r/u/s) Command [run=1/1]
0 running /var/folders/11/50ttcfms01ddxpsrjnxtn4f80000gn/T//ts-out.I7G4pq sh hoge.sh
1 queued (file) sh hoge.sh並列処理数を変える
task-spoolerは初期設定だと最大並列処理数は1つです。
$ ts -S
1下記のコマンドで変更が可能です。
$ ts -S 2何度かhoge.shを実行した後、もう一度ジョブを確認してみます。
$ ts
ID State Output E-Level Times(r/u/s) Command [run=2/2]
2 running /var/folders/11/50ttcfms01ddxpsrjnxtn4f80000gn/T//ts-out.roBW9K sh hoge.sh
3 running /var/folders/11/50ttcfms01ddxpsrjnxtn4f80000gn/T//ts-out.R6m1Zd sh hoge.sh
4 queued (file) sh hoge.sh
5 queued (file) sh hoge.sh
6 queued (file) sh hoge.sh
0 finished /var/folders/11/50ttcfms01ddxpsrjnxtn4f80000gn/T//ts-out.I7G4pq 0 9.54/3.15/4.92 sh hoge.sh
1 finished /var/folders/11/50ttcfms01ddxpsrjnxtn4f80000gn/T//ts-out.4iEouz 0 10.00/3.33/5.22 sh hoge.shrunningの下図が2個に増えているのが分かります。ちなみにジョブIDに着目してみると昇順で処理が進んでいるのでFIFO方式になっていることも見て取れます。
以上です。