目標
今回の目標はRabbitMQを使い並列処理クラスタを構築する事です。昨今のスパコンは一つのCPUの性能を高めるよりも、汎用的なCPUを大量に並べて処理能力を上げる方が一般的です。
例えば10秒掛かる処理が10個あるとして、1台の計算機で全てやろうとすると100秒掛かりますが、2台の計算機なら50秒で終わりますし、10台の計算機なら10秒で終わります。つまり並列処理をさせることで全体の計算に掛かる時間を短くするということを実現したいと思います。
まずメッセージングミドルウェアとは
RabbitMQはメッセージングミドルウェアと呼ばれていますが、メッセージングミドルウェアというのは異なるアプリ同士が双方向に情報をやり取りするためのソフトウェアのことです。MOM(Message-oriented-middleware)を使うと次のような良い事があります。※日本語だとメッセージ指向ミドルウェアといいます。
メッセージキューイングを利用した非同期処理
仮にMOMを使わないECサイトのようなWebアプリを作ったとします。その場合ざっくりとですが次の様な流れになるかと思います。
- エンドユーザは商品をカートに入れ、フォームを入力して購入ボタンをクリックします。
- 購入情報が管理サーバに送信され、ユーザ認証やデータ書き込みなどのDBとやり取りをしたり、在庫チェックや発送準備を行います。
- 2.の処理が完了したことを確認しエンドユーザにレスポンスを返して購入が完了する。
これの何処に問題があるのかと言いますと、2.の処理中エンドユーザはひたすら待ち続けなければならないという点です。
そこでキューというデータ領域に購入情報をストアさせておき、順次管理サーバが処理していくというのが非同期処理の良い所です。
保守性の高い開発
又、MOMを利用するとサービス毎に開発が可能になります。ここでもECサイトを例にしますが、1.と2.の処理部分を順番に作っていくよりも、「1.部分は私達が作ります。最終的に~の様なメッセージを送りますので」「承知しました。ではそのメッセージに合うように2.部分は私達が作ります」と言う方が効率が良いですし、汎用性もあります。
他にもリスクを一元管理しないことによる耐障害性向上など様々なメリットがあります。
構築
RabbitMQインストール
# yum -y install epel-release
# yum -y update
# yum -y install erlang
# rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
# wget https://dl.bintray.com/rabbitmq/all/rabbitmq-server/3.6.14/rabbitmq-server-3.6.14-1.el7.noarch.rpm
# yum -y install rabbitmq-server-3.6.14-1.el7.noarch.rpm
# systemctl enable rabbitmq-server.service
# systemctl start rabbitmq-server
# rabbitmq-plugins enable rabbitmq_management- erlangパッケージインストール
- 並列処理系ライブラリ
- RabbitMQはアーランで開発されています。依存解決が面倒ならyumでもインストール出来ます。その際はEPELリポジトリを追加して下さい。
- マネジメント用のポート開放
- 15672/tcp
- 80/tcp
- 443/tcp
- プラグインインストール
- GUIで操作するため
メッセージプログラム
Python環境
# yum -y install epel-release
# yum -y install python34 python34-pip
# yum -y install python3-pip
# pip3 install pikapikaとはPythonで書かれたAMQPライブラリ。
受信側プログラム
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume('hello', callback, auto_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()送信側プログラム
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()試験
受信用と送信用のターミナルをそれぞれ立ち上げてプログラムを実行してください。メッセージを送信する度に受信されれば成功です。
用語解説
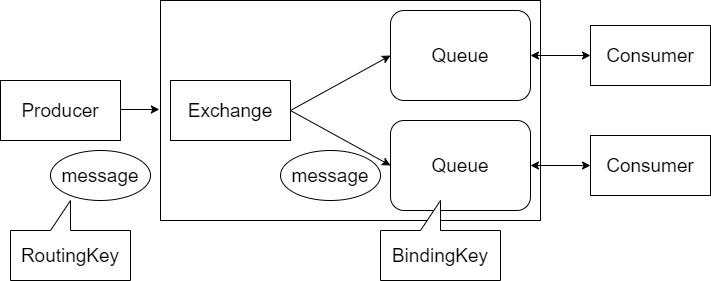
- Producer
- メッセージをキューに投げる
- Consumer
- キューをブローカーから受け取る
- Broker
- キューイングされたメッセージを保持しConsumerに渡す
- Queue
- メッセージを入れる入れ物
- Message
- ProducerとConsumerの間でやり取りされる文
- Exchange
- メッセージのルーティング方式
- メッセージに付与されるRoutingKeyとキューに付与されるBindingKeyを比べて一致するキューにメッセージを入れる。
- direct/fanout/topic
- 完全一致/ブロードキャスト/部分一致
よく使うコマンド
本題から逸れますがRabbitMQでよく使うコマンドもまとめておきます。
$ rabbitmqctl add_user user01 cluster2305
Creating user "user01" ...
...done.
$ rabbitmqctl list_users
Listing users ...
guest [administrator]
user01 []
...done.
$ rabbitmqctl set_permissions user01 '.*' '.*' '.*'- ユーザ追加
- rabbitmqctl add_user 【ユーザ名】 【パスワード】
- 権限付与
- 左から「設定変更/書き込み/読み込み」権限
- vhost単位で設定可能(今回は未指定)